
We’ve all seen the tutorials: “Build a RAG system in 5 minutes with 10 PDFs.” It looks like magic, until you try to do it for a organisation with over 1 million legacy documents and a legal requirement for perfect metadata tracking.
As I’ve been deep in the trenches building enterprise-level Retrieval-Augmented Generation (RAG) systems using both Vector and Graph databases, I’ve hit a wall that the guides don’t mention. We are moving from a world of “semantic search” to a world of “archive scraping,” and our specialised databases aren’t ready to do it alone.
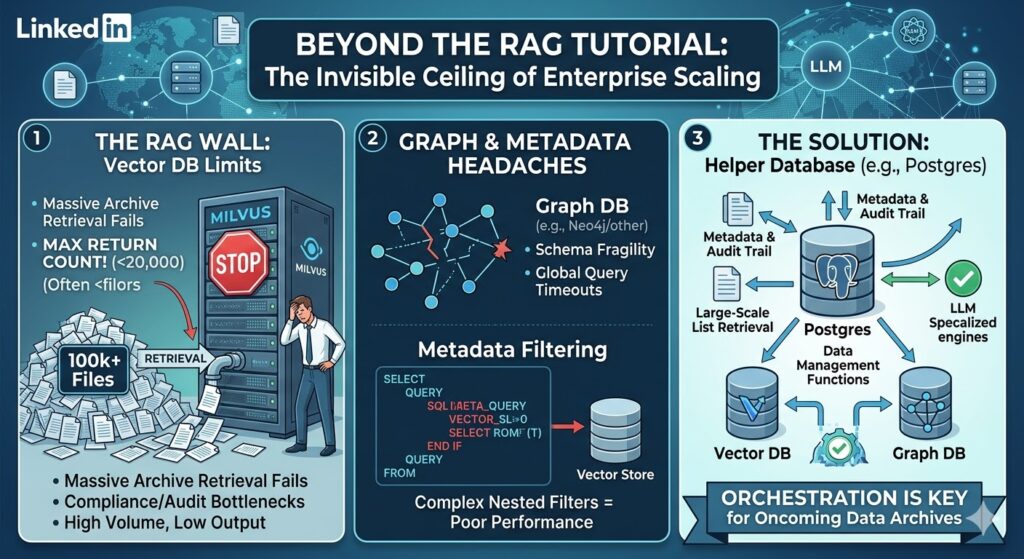
1. The “Top-K” Trap: When Milvus (and others) Say “No”
One of the most immediate “real-world” shocks is hitting the return limits of specialised vector stores. Take Milvus, for instance. It is a beast for high-speed similarity search, but it has a hard topk limit (often capped around 16,384).
In an enterprise setting, you frequently need to retrieve lists of files or chunks numbering in the 10s to 100s of thousands, perhaps for a batch re-ranking process, an audit, or a massive data-summarisation task over an entire archive. When your database refuses to return more than a few thousand results because its internal architecture is optimised for latency rather than volume, your pipeline breaks.
2. The Relationship Rigidity of GraphRAG
We added Graph Databases to the mix to solve for “multi-hop” reasoning, connecting meeting minutes to pdf appendix files. But GraphRAG at scale introduces its own set of headaches:
- The Global Query Problem: Asking a “global” question over a massive graph (e.g., “Summarise the main themes across all 50,000 meeting papers”) is computationally expensive and often results in “timeout death.”
- Schema Fragility: Enterprise data is messy. If your ontology isn’t perfect, your GraphRAG retrieval becomes a noisy mess that confuses the LLM more than it helps.
3. The Metadata Bottleneck
Vector databases are great at math (vectors) but often mediocre at “boring” data management. When you need to filter by complex, nested criteria, like “All PDF files created between 2018-2020, tagged ‘Confidential’, but excluding those from the HR department”, the performance of specialised vector stores can plummet. They weren’t built to be relational powerhouses; they were built to find the nearest neighbor in a high-dimensional space.
4. The RAM Bottleneck (The HNSW Tax)
Most vector databases use the HNSW (Hierarchical Navigable Small World) algorithm for speed. For HNSW to be fast, the index must live in RAM.
- 100 million vectors can easily require 300GB to 600GB of RAM.
The Solution: Why You Need a “Helper” Database
The hard lesson I’ve learned is that an enterprise RAG system is not just a vector store; it is a coordinated data architecture. You cannot rely on your vector or graph DB to be the “source of truth” for your metadata or your large-scale retrieval logic.
You need a Helper Database.
I personally use Postgres (with the pgvector extension) as my “Control Plane” database. While dedicated stores like Milvus handle the heavy lifting of 512-dimensional math, Postgres handles the “Enterprise Reality”:
- Massive List Management: When I need to fetch IDs for 200,000 files, Postgres doesn’t blink. I can join, filter, and paginate through millions of rows without hitting a topk wall.
- Audit & Lineage: Postgres allows me to track why a document was retrieved, which user accessed it, and when the embedding was last updated.
- Hybrid Functionality: With tools like pgai and vectorscale, Postgres is becoming the “glue” that allows us to integrate helper functionality, like deduplication, permission-checking, and batch-processing, directly into the retrieval flow.
The Coming Deluge
We are about to face a “deluge” of data-scraping archives. As companies point their RAG systems at 20-year-old archives, the “5-minute tutorial” architecture will crumble. We need to stop treating Vector and Graph databases as silos and start integrating them into mature relational ecosystems.
The future of RAG isn’t just better embeddings; it’s better data orchestration.